Motivation
Our goal is to predict the success of Threadless t-shirt designs based on semantic image features extracted using image recognition software. Threadless is a website where customers can not only buy apparel, but also submit their own designs to design competitions. Winners of competitions are then sold on the main Threadless store. While users vote and rate clothing designs, the ultimate winners are chosen by a team of Threadless workers. Predicting design success is useful for tailoring product and design curation to the Threadless target market as well as to subgroups of customers who already purchase clothing from Threadless.
Solution
We have a dataset of Threadless clothing designs that includes the total number of votes they received as well as their average ratings. We used the average rating of each design (weighted by total number of votes) we to score designs as "good" or "bad". To this dataset we added semantic image tags generated by running the design images through image recognition software. The software we used is called DeepSentiBank developed at Columbia University. This produces 2,089 adjective-noun pairs (e.g., beautiful zombie, bloody flower) and ranked concept scores for each pair. We use these pairs as attributes to predict the success of t-shirt designs. The full dataset features 34,952 data points between February 2010 and December 2011.
Testing and Training
For our training set we defined success as having an average score in the top 2,500 scores of t-shirt designs. We took 2,500 images with the highest user scores and labeled them as good designs, and took the 2500 images with the lowest user scores as bad designs. Our test dataset also included 5,000 randomly chosen instances from 34,952 data points.
Results
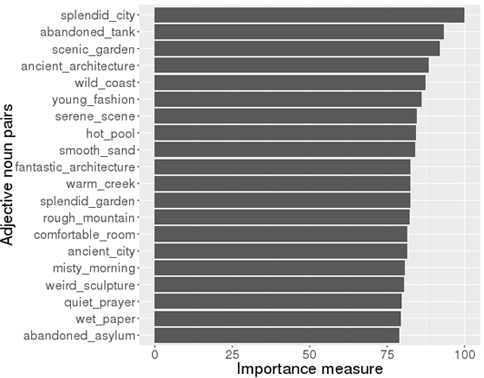
We trained multiple machine learning models using a variety of machine learning algorithms including KNN, SVM, and Naive Bayes. The Naive Bayes learner performed the best with an accuracy of 53.62% on our test dataset. We achieved 68.54% accuracy on our training set in cross-validation, indicating some amount of overfitting to the training set. The chart shows the 20 features with the highest important scores. Unfortunately, it is difficult to make a general statement about the top 20 list of features, but conventional adjective noun pairs such as beautiful flower, clean water and cute cat are not on the list. This may imply that some novel or unique concepts can help designs gain a higher vote score.
The 20 highest rated Threadless designs trained on

The 20 worst rated Threadless designs trained on